[AWS] – “서버가 죽었다! 탐정이 되어 장애 해결하기”
[AWS] – “서버가 죽었다! 탐정이 되어 장애 해결하기”

문제 상황
적지 않은 상품 데이터를 삽입하고 관리하는, Django 와 DRF 로 구동된 API 서버가 구동되고 있습니다. 아래와 같은 데이터죠.
{
"product_id": "test_product_1",
"name": "goddessana's bag"
}그리고 클라이언트 측에서 18만 개 정도의 데이터를 삽입했을 때에, 아래와 같은 장애가 발생했습니다.
상품이 많아져서 그런지, 관리자 페이지에서 상품 조회가 너무 느려요. 가끔 500 에러나 타임아웃도 발생합니다.
저는 개발자입니다. 이 문제를 해결해야 합니다. 오늘은 이 이야기입니다. 왜 500 에러가 발생했거나, Django 로 구현된 웹 페이지가 타임아웃이 날 정도로 응답을 주지 못하는 상황이 발생했을까요? 문제는 뭐였고, 어떻게 해결할 수 있을까요?
첫 번째: Caddy 로그 확인하기
간략하게, 서버는 AWS LightSail 을 웹 서버로, LightSail DB (PostgreSQL) 을 데이터베이스 서버로, LightSail Storage 를 정적 파일 저장소로 사용하고 있습니다. 대략 아래와 같은 구성이죠.

대략 이런 경우 서버 에러를 확인해봐야 합니다. 진짜 lightsail 인스턴스가 죽었는지, Wsgi Application(Django) 에서 에러가 났는지, 리버스프록시 중 에러가 났는지 등등을 말이죠.
이 프로젝트에서는 Caddy 라는 웹 서버를 사용하고 있습니다. 초기 세팅 시 https 인증서 설치 등을 빠르게 하기 위해 시도해 보았고, 성공적으로 운영되고 있었죠.
Caddy 서버는 정상 동작 중입니다. 아래는 액세스 로그의 한 줄을 발췌한 것인데, 로그를 분석해 봅시다. 아마 여기서 단서를 찾을 수 있을 것 같습니다.
{
"size": 0,
"msg": "handled request",
"ts": 1759483517.322537,
"bytes_read": 0,
"user_id": "",
"status": 502,
"resp_headers": {
"Server": [
"Caddy"
],
"Alt-Svc": [
"h3=\":443\"; ma=2592000"
]
},
"request": {
"client_ip": "...",
"remote_ip": "...",
"tls": {
"resumed": false,
"version": 772,
"proto": "http/1.1",
"server_name": "...",
"cipher_suite": 4865
},
"proto": "HTTP/1.1",
"host": "...",
"method": "GET",
"uri": "/api/products/?page=47&page_size=50",
"remote_port": ".....",
"headers": {
"Accept": [
"application/json"
],
"User-Agent": [
"GuzzleHttp/7"
],
"Authorization": [
"REDACTED"
]
}
},
"duration": 31.8161947,
"level": "error",
"logger": "http.log.access.log0"
}음.. 먼저 502 에러가 보입니다. HTTP 502 Bad Gateway 에러는 서버가 게이트웨이나 프록시 서버 역할을 하면서 업스트림 서버로부터 유효하지 않은 응답을 받았다는 것을 의미합니다.
조금 아래로 살펴보면, request_ip 와 client_ip 가 모두 같은 것을 확인할 수 있습니다(가렸지만요). 이것은 요청을 한 클라이언트와 서버가 같은 Lightsail 인스턴스라는 것을 의미합니다.
caddy 서버 로그 문서를 확인해 보면, duration 의 기본 단위는 “초” 입니다. 그러니까, 리버스프록시하기 위해 Gunicorn 서버에 요청을 보냈지만 31초라는 시간이 걸렸고, 이것이 타임아웃으로 이어졌다는 것입니다.
여기서 얻을 수 있는 단서는, Caddy 서버는 정상 동작했지만 Gunicorn Worker 가 응답하는 데에 시간이 많이 걸렸고, 시간이 많이 걸림에 따라 Caddy 가 502 에러를 발생시켰다는 겁니다.
좋아요, 첫 번째 단서를 찾았습니다. 이제 Gunicorn 을 살펴볼 차례입니다.
두 번째: Gunicorn 로그 확인하기
저는 Gunicorn 을 linux system service 에 등록하여 서빙하고 있습니다. 그렇게 하면, journalctl -u gunicorn -n 100 과 같은 명령어로 gunicorn 프로세스의 로그를 확인할 수 있죠. 로그는 아래와 같았습니다.
Oct 03 09:38:09 ip-172-26-8-250 gunicorn[1407880]: [2025-10-03 09:38:09 +0000] [1407880] [CRITICAL] WORKER TIMEOUT (pid:1412221)
Oct 03 09:38:10 ip-172-26-8-250 gunicorn[1407880]: [2025-10-03 09:38:10 +0000] [1407880] [ERROR] Worker (pid:1412221) was sent SIGKILL! Perhaps out of memory?
Oct 03 09:38:10 ip-172-26-8-250 gunicorn[1412225]: [2025-10-03 09:38:10 +0000] [1412225] [INFO] Booting worker with pid: 1412225
Oct 03 09:38:41 ip-172-26-8-250 gunicorn[1407880]: [2025-10-03 09:38:41 +0000] [1407880] [CRITICAL] WORKER TIMEOUT (pid:1412215)
Oct 03 09:38:42 ip-172-26-8-250 gunicorn[1407880]: [2025-10-03 09:38:42 +0000] [1407880] [ERROR] Worker (pid:1412215) was sent SIGKILL! Perhaps out of memory?
Oct 03 09:38:42 ip-172-26-8-250 gunicorn[1412227]: [2025-10-03 09:38:42 +0000] [1412227] [INFO] Booting worker with pid: 1412227
Oct 03 09:40:12 ip-172-26-8-250 gunicorn[1407880]: [2025-10-03 09:40:12 +0000] [1407880] [CRITICAL] WORKER TIMEOUT (pid:1412212)
Oct 03 09:40:13 ip-172-26-8-250 gunicorn[1407880]: [2025-10-03 09:40:13 +0000] [1407880] [ERROR] Worker (pid:1412212) was sent SIGKILL! Perhaps out of memory?
Oct 03 09:40:13 ip-172-26-8-250 gunicorn[1412232]: [2025-10-03 09:40:13 +0000] [1412232] [INFO] Booting worker with pid: 1412232어느 정도 반복된 패턴이 보입니다. Gunicorn Worker 가 어떤 이유로든 WORKER TIMEOUT 으로 죽고, Gunicorn 측에서는 어떤 이유로 응답이 없는지 모르니 “Perhaps out of memory?” 와 같이 “이거 WSGI(Django) 애플리케이션에서 OOM 뜬 거 아니야?” 와 같은 에러 메시지를 보여주고 있죠. 시스템 상태를 확인해 보면, gunicorn 서비스가 사용하고 있는 메모리는 300~500MB 사이인 것으로 보입니다.
요약하자면, 아직은 원인은 모르지만 Gunicorn worker 와 연결된 callable WSGI Application, 즉 Django 앱이 응답하지 않았다는 겁니다. Gunicorn 시스템 프로세스는 계속 Gunicorn 워커 생성 재시도를 반복하고, 그러니 중간에 “가끔” 되면 간헐적으로 페이지가 동작하고.. 이게 반복되고 있었던 거죠. 서버가 2GB 정도의 메모리를 가지고 있다는 것을 고려하면, OOM 보다는 정말 어떤 이유로든 응답이 늦게 온 것으로 추측할 수 있습니다. 실제로 sudo dmesg -T | grep -i "kill" 의 결과는 너무나도 깨끗했죠.
여기서 얻을 수 있는 단서는 Gunicorn 은 자신의 일을 매우 열씸히 잘 하고 있었다는 겁니다. Django 앱이 오늘은 연락할까, 하는 마음에 계속 Worker 에게 연락하고 있었던 거죠. 이 상황에서 우리의 의심의 눈초리는 Django 앱으로 향합니다. Django 는 왜 상대방 마음 터지게 연락을 늦게 하고 있던 걸까요?
세 번째: Django 타임아웃 확인하기
여기까지 알 수 있는 것은, “Caddy 리버스 프록시 서버가 Gunicorn 으로부터 Timeout. 하지만 Gunicorn 워커는 자신의 임무를 계속 하고 있었음. 문제는 Django 가 응답할 때에 있음.” 입니다. 아쉽게도, 제 지식 수준에서는 제가 로그를 확인할 수 있는 방법은 여기서 없었습니다. 파이썬에서 발생하는 에러들이 Gunicorn 로그에 찍히는데, Gunicorn 로그는 생성되지마자 Timeout 으로 죽어버리니까요.
아마 Gunicorn worker 가 어떻게 부팅되는지를 알아보면 조금 더 파고들 수 있을 것 같아요.
Gunicorn 의 동작 과정
Gunicorn 문서에 따르면, Gunicorn 은 Master 프로세스와 그 하위 프로세스가 존재합니다. 마스터 프로세스는 워커 프로세스에 대해 알지 못하고, 여러 개의 워커 프로세스를 관리하는 식이죠. 위에서 보셨던 로그를 기억하시나요?
Oct 03 09:38:42 ip-172-26-8-250 gunicorn[1412227]: [2025-10-03 09:38:42 +0000] [1412227] [INFO] Booting worker with pid: 1412227
Oct 03 09:40:12 ip-172-26-8-250 gunicorn[1407880]: [2025-10-03 09:40:12 +0000] [1407880] [CRITICAL] WORKER TIMEOUT (pid:1412212)
Oct 03 09:40:13 ip-172-26-8-250 gunicorn[1407880]: [2025-10-03 09:40:13 +0000] [1407880] [ERROR] Worker (pid:1412212) was sent SIGKILL! Perhaps out of memory?맞아요, 마스터 프로세스가 각 워커가 타임아웃된 것들을 확인하고, 새로운 워커를 생성하는 식으로 관리를 하고 있었던 겁니다.
아무튼, Gunicorn 의 동작은 마스터 프로세스의 실행으로 시작됩니다. 마스터 프로세스는 곧 자식 프로세스를 만듭니다. 아마 Gunicorn 으로 프로세스를 시작하였다면 gunicorn --bind 0.0.0.0:8000 --workers 3 config wsgi:application 과 같은 명령어를 사용하셨을 텐데, Gunicorn 은 이 옵션을 보고 워커 프로세스를 만드는 겁니다.
그러면, 워커 프로세스들은 Django 의 WSGI 애플리케이션을 바라보게 됩니다. 워커들은 Django 애플리케이션을 실행하려고 시도할 것이고, 실제 타임아웃은 이 지점에서 발생했던 거죠. 그래서 저는 로컬 환경에서 개발 서버를 실행하였고, 애플리케이션 시작 시 꽤 많은 시간이 걸린다는 것을 깨닫게 됩니다.

정확히 이 상황에서 많은 시간이 걸렸습니다. 보아하니, Django 의 Check Framework 검사는 성공적으로 통과된 것 같습니다. (https://docs.djangoproject.com/en/5.2/topics/checks/) Django 의 Check Framework 는 Django 앱에 어떤 문제는 없는지, 예컨대 settings.py 에 잘못된 설정 등이 있는지를 검사하는 내장 프레임워크입니다.
Django 앱은 시스템 체크를 통과하면 마이그레이션 체크를 수행하게 되고, 몇 분 후 저는 이러한 에러를 만나게 됩니다.
django.db.utils.OperationalError: connection to server at "라이트세일-DB-서버-엔드포인트" (라이트세일-DB-서버), port xxxx failed: timeout expired
잡았어요. 문제는 요 놈이었습니다.
네 번째: DB 연결이 오래 걸린다
DB 연결이 오래 걸립니다. 저는 라이트세일에서 DB 관련 지표를 찾아보았고, 아래와 같은 결과를 볼 수 있었습니다. 각각 데이터베이스 연결 수 – CPU 사용률 – 대기열 깊이를 나타내는 그래프들입니다.
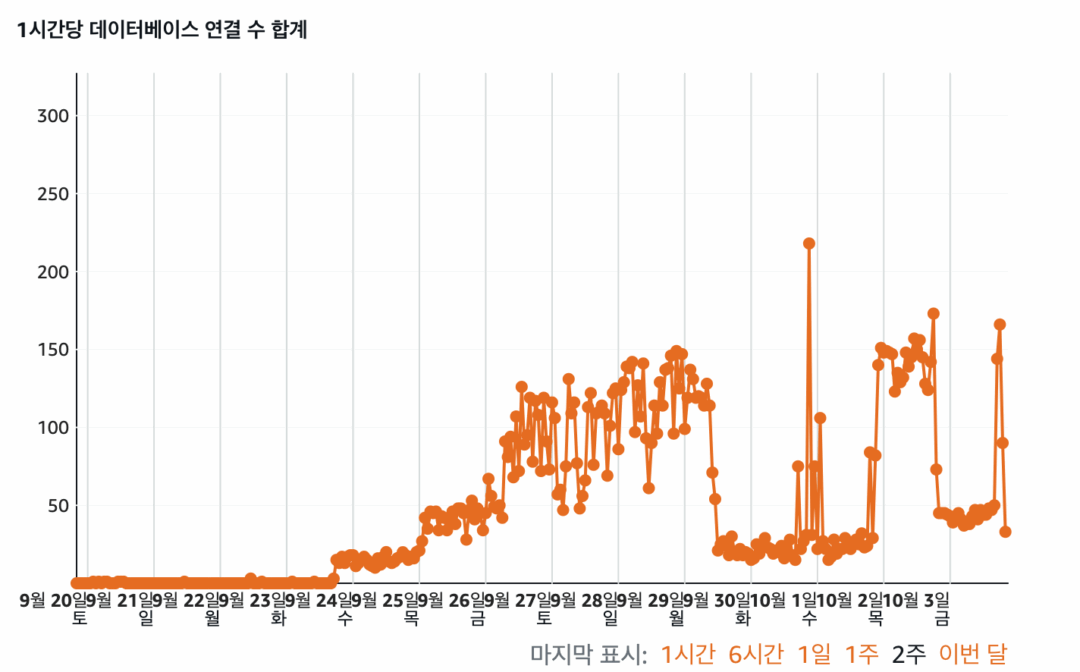
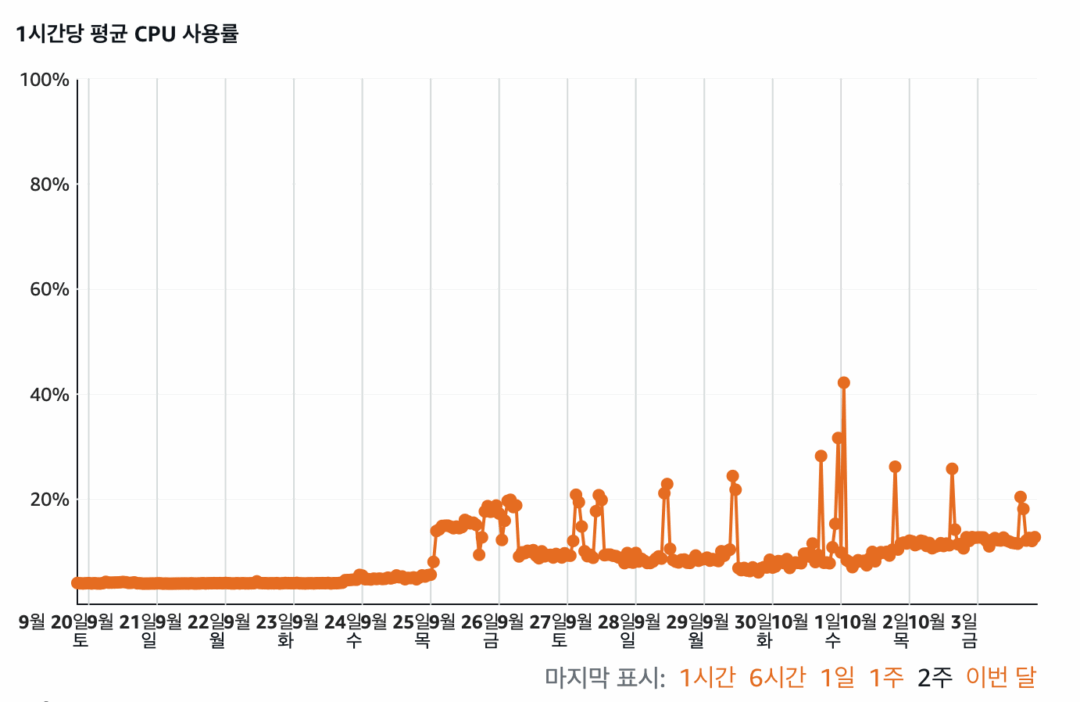
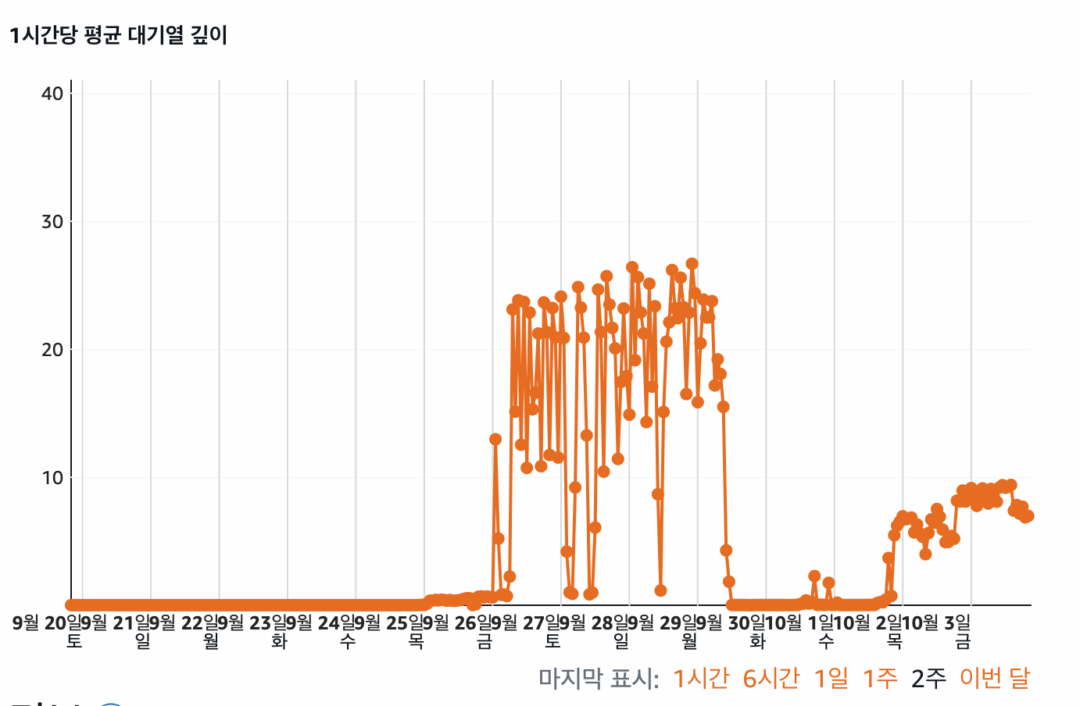
어떤 이유로든 데이터베이스 연결 수가 급증했고, CPU 사용량도 툭툭 튀었으며 대기열 깊이(디스크에 “처리해주세요” 하고 대기 중인 작업의 줄) 또한 급증했습니다. 예측해 보건대 연결 수가 급증하고, CPU 사용량이 증가하며, 버스트 가능한 CPU를 모두 소진하고 처리 속도 등을 확 줄여진 것처럼 보였죠.
“라이트세일 데이터베이스 내부적으로 CPU 버스트 한계치가 존재하고, 성능에 대한 제한을 걸고 있기 때문에, 수많은 DB 사용 이후 성능이 저하되었을 것이다 / 혹은 네트워크에 제한을 두었을 것이다.” 는 모두 저의 추측입니다.
…까지가 제 생각이었는데, Lightsail DB 는 디스크 읽기/쓰기 자체 속도가 느린 고질적인 문제가 있다고 합니다.
https://docs.aws.amazon.com/lightsail/latest/userguide/amazon-lightsail-faq-block-storage.html
>> For customers with applications that require sustained IOPS performance, high amounts of throughput per disk, or that are running large databases like MongoDB, Cassandra, etc., we recommend using Amazon EC2 with GP2 or Provisioned IOPS SSD storage instead of Lightsail.
>> 지속적인 IOPS 성능이 필요하거나 디스크당 높은 처리량이 요구되는 애플리케이션을 보유한 고객, 또는 MongoDB, Cassandra 등과 같은 대규모 데이터베이스를 운영하는 고객의 경우, Lightsail 대신 Amazon EC2와 GP2 또는 Provisioned IOPS SSD 스토리지를 사용하는 것을 권장합니다.
일단 스냅샷 -> 고가용성 데이터베이스 생성
현재 어떤 이유로든 DB 가 연결을 수락하는 데에 너무 많은 시간이 드는 상태입니다. 하여 LightSail DB 에서 스냅샷을 생성한 다음 30달러 플랜의 고가용성 데이터베이스 인스턴스를 하나 생성했습니다. 비밀번호, 데이터 등은 모두 동일하므로 Django 애플리케이션에서는 단지 URL 주소만 바꿔주면 됩니다. (DB Endpoint)
참고: 고가용성 데이터베이스 또한 대량 데이터 삽입이 시작되자 문제를 해결하는 데에 도움이 되지 않았습니다. 문제는 위에서 언급했듯이 Disk IOPS 때문이었다고 판단되었습니다.
애플리케이션 코드의 문제
목록 조회 쿼리에 대한 인덱스 부재
생각해 보면, 문제가 발생한 시점은 20만 건+ 상품 데이터 삽입 며칠 후입니다. 따라서 가장 먼저 살펴볼 것은 상품 관련코드입니다. 관리자 페이지에서, “상품 관리” 페이지에 접속하면 쿼리는 아래와 같습니다.
SELECT "상품_테이블"."id",
-- 필드들 ...
"공급사_유저_테이블"."id",
"공급사_유저_테이블"."code",
"공급사_유저_테이블".",
-- 필드들 ...
FROM "상품_테이블"
INNER JOIN "공급사_유저_테이블"
ON ("상품_테이블"."supplier_id" = "공급사_유저_테이블"."id")
ORDER BY "상품_테이블"."updated_at" DESC
LIMIT 1000 OFFSET 400;18만 개 중 1000개 데이터를 건너뛰고 400개 데이터를 가져오는 데에 3초 정도 걸렸습니다. 아주 못 기다릴 정도는 아니지만 쾌적하다고는 절대 말 못하는 수치이죠. 여기서 데이터베이스는 아래의 작업을 수행합니다.
상품_테이블테이블과공급사_유저_테이블테이블을 조인한 모든 결과를 메모리나 임시 공간에 가져온 후, 이 거대한 데이터를updated_at기준으로 처음부터 끝까지 정렬합니다.- 정렬이 끝나면, 앞의 1000개 데이터를 건너뛰기 한 다음, 400개 데이터를 가져오죠.
.. 그러면 상품 데이터의 개수가 많아질수록, 데이터베이스는 정렬 -> 건너뛰기를 수행하고 이것은 매우 큰 비효율을 발생시킵니다. 쿼리 플랜은, 아래와 같습니다.
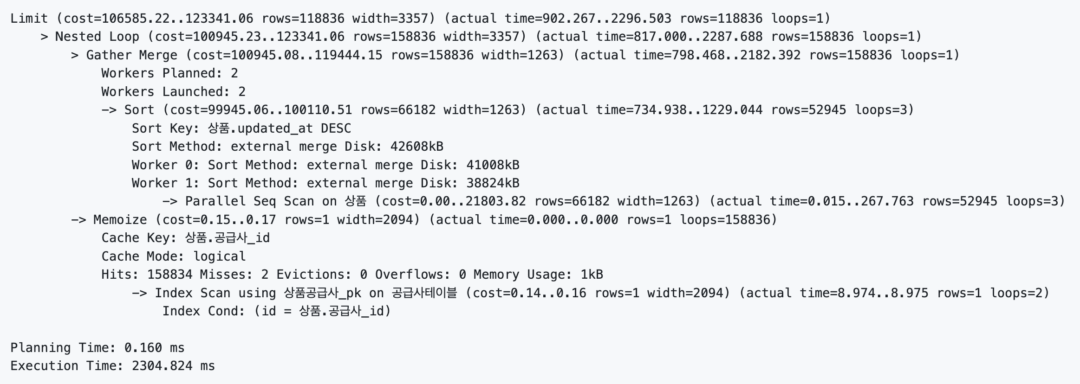
- 먼저 테이블은 전체 스캔했고,
external merge Disk방식으로 디스크에 정렬을 했습니다.- 현재 라이트세일 DB 사양은 2코어인데, 코어 2개를 모두 사용해서 (
Workers Planned: 2) 정렬을 한 것을 확인할 수 있죠. - 이 과정에서 실행 시간은 1.2초 정도 됐습니다.
- 현재 라이트세일 DB 사양은 2코어인데, 코어 2개를 모두 사용해서 (
- 그리고, 각 워커가 정렬한 결과를 머지하는 과정이 끝났을 때에는 이미 2초가 지난 시점이었습니다.
.. 그래서 인덱스를 주었습니다. 공급사_id(fk), updated_at 에 인덱스를 걸었습니다. 실행 결과는 아래와 같았어요.

Index Scan using partners_suppliercompany_pkey로 상품 테이블에서 공급사_id 와 일치하는 상품들을 찾는 작업을 수행합니다.PostgreSQL은Memoize를 통해 단기 캐시를 수행하고, 15만 캐시가 모두 hit 하였습니다. 실제 db 스캔은 2번밖에 이루어지지 않았습니다.Index Scan Backward using 상품_인덱스_updated_at_d82a41c3 on 상품을 통해 생성한 인덱스를 읽었습니다. 인덱스 생성 전에는Sort과정이 필요했지만, 지금은 그렇지 않습니다. 이 곳에서 물리적인 I/O 가 일어났습니다.
좋아요! 2304ms -> 254ms 로 실행 시간을 꽤 최적화할 수 있었습니다.
데이터 삽입 시 발생하는 오버헤드
지금까지, 우리의 클라이언트는 상품 1개 삽입당 1개의 API 를 호출하여 총 18만 번 호출토록 했습니다. 이것은 우리가 생각하고 있는 DB 부하의 주요 원인이기도 했죠.
상품 1개를 삽입 -> 삽입된 상품의 정보를 반환하는 API 대신, 대량 삽입 요청 -> 백그라운드로 태스크로 보내고 API 는 태스크의 생성 결과를 리턴하도록 합시다. 이렇게 하면, 상품 한 개를 삽입할 때마다 하나의 트랜잭션, 서버 연결, DB 연결을 수행하는 대신 많은 수의 상품을 한 번의 트랜잭션과 한 번의 DB 연결로 수행할 수 있죠. 연결 수, 네트워크 통신 시간, 대기열 깊이 또한 많이 최적화할 수 있습니다.
하여 저는 Celery 기반의 백그라운드 태스크로 데이터 삽입 API 를 구현하였으며, 내부적으로 1000개 상품 삽입에 3분 정도의 시간이 걸리도록 변경되었습니다.
하지만, 클라이언트 측에서 기술적인 문제로 데이터를 1000개씩 바꾸는 것은 쉽지 않다는 답변을 받았고, 상품 삽입이 재개될 때에는 1000개 상품 삽입 -> 1000번의 API 호출 -> 1000개의 Celery Background Task 생성 이라는 결과가 나오게 되었습니다. 물론 1000번의 추가적인 Celery Task 관련 데이터가 또 쌓이게 되지만, 기본적으로 데이터 삽입 시 네트워크 I/O(이미지 관련)가 발생하고, Gunicorn worker 가 동기식인 점을 감안하면 잘 한 결정이었다고 생각합니다. 이미지 서버나 DB Connection 과 같은 I/O 때문에 Gunicorn worker 가 대기를 하거나 죽는 것보단, 다른 요청을 처리하는 것이 낫다고 생각하기 때문입니다.
진짜 문제.. Disk IOPS
고가용성 데이터베이스 생성으로 하드웨어도 업데이트했고, Network I/O 가 발생하는 삽입 프로세스를 모두 Celery worker 로 마이그레이션도 했습니다. 하지만 새로운 버전을 배포하고, 서버는 계속 죽었죠. 재부팅해도, 죽기까지의 시간이 업그레이드 전에 비해 아주 조금 줄어들었을 뿐, 결국 죽어버렸다는 거죠.
그래서 저는 속해 있는 개발자 모임 단톡방에 저의 고민을 올렸고, 한 분께서 어떤 링크를 던져주시게 됩니다. 친절한 발췌문과 함께요.
https://docs.aws.amazon.com/lightsail/latest/userguide/amazon-lightsail-faq-block-storage.html
Lightsail 블록 스토리지 디스크는 SSD(Solid State Drive)를 사용합니다. 이 유형의 블록 스토리지는 저렴한 가격과 우수한 성능의 균형을 이루며 Lightsail에서 실행되는 대부분의 워크로드를 지원하도록 설계되었습니다. 지속적인 IOPS 성능, 디스크당 높은 처리량이 필요한 애플리케이션을 사용하거나 MongoDB, Cassandra 등과 같은 대규모 데이터베이스를 실행하는 고객의 경우 Lightsail 대신 GP2 또는 프로비저닝된 IOPS SSD 스토리지를 사용하는 Amazon EC2를 사용하는 것이 좋습니다.
네, 문제는 Disk 의 IOPS 였다는 것입니다. 아래의 그림이 기억 나시나요?
한 시간당 평균 대기열 깊이가 30 가까이를 찍고 있습니다. 이 것이 올라간 이유는,
- 데이터 삽입 요청을 짧은 시간 내에 많이 진행하였고,
- 안타깝게도 우리 Lightsail 데이터베이스의 디스크는 이 모든 작업을 처리하기에 힘들었습니다.
- 디스크의 쓰기 처리 속도에 비해, 많은 삽입 요청은 ‘디스크 요청 줄서기’ 를 만들어내 버렸고,
- 이 ‘디스크 요청 줄서기’ 가 스무 명.. 서른 명까지 올라가 버리다 보니
- 데이터베이스가 단 하나의 레코드 삽입에도 수십 초가 걸려버렸다는 거죠.
그래서, 즉시 RDS 인스턴스를 디스크 볼륨 gp3 과 함께 구성해 마이그레이션했습니다.

그리고 서버를 다시 구성하였고, 현재까지 데이터베이스는 짱짱하게 운영되고 있습니다.
Cloudwatch 대시보드 구성
아무래도 ‘장애가 발생했으니, 더 좋은 인스턴스로 마이그레이션해서 서버가 죽지 않게 만들었다!’ 면 조금 찝찝하죠. 앞으로도 장애가 발생했을 때, 어떤 것이 문제인지, 아니면 어떤 것이 문제인지를 가늠할 수 있는 지표가 있으면 좋겠다고 생각했습니다.
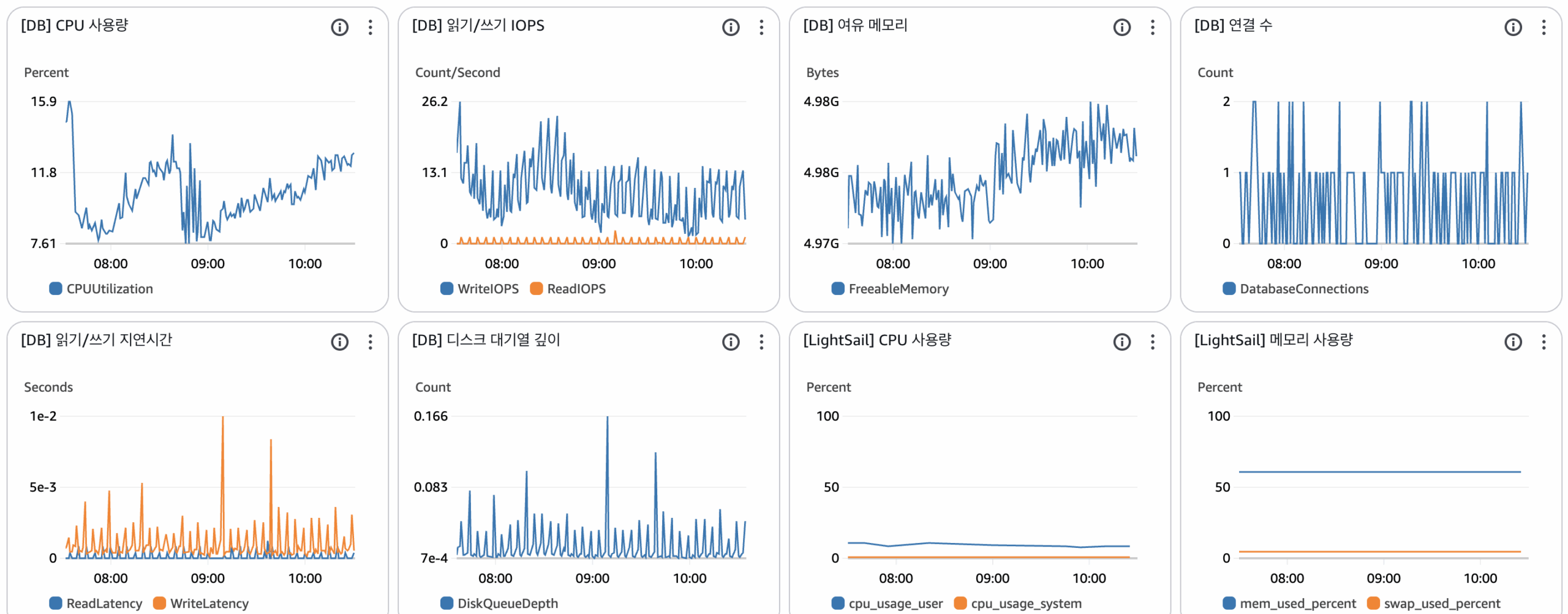
그리하여 위와 같은 CloudWatch 대시보드를 구성했고, 이상 발생 시 기존의 Lightsail 대시보드보다 쉽게 여러 지표를 확인하고 분석할 수 있게 되었습니다.
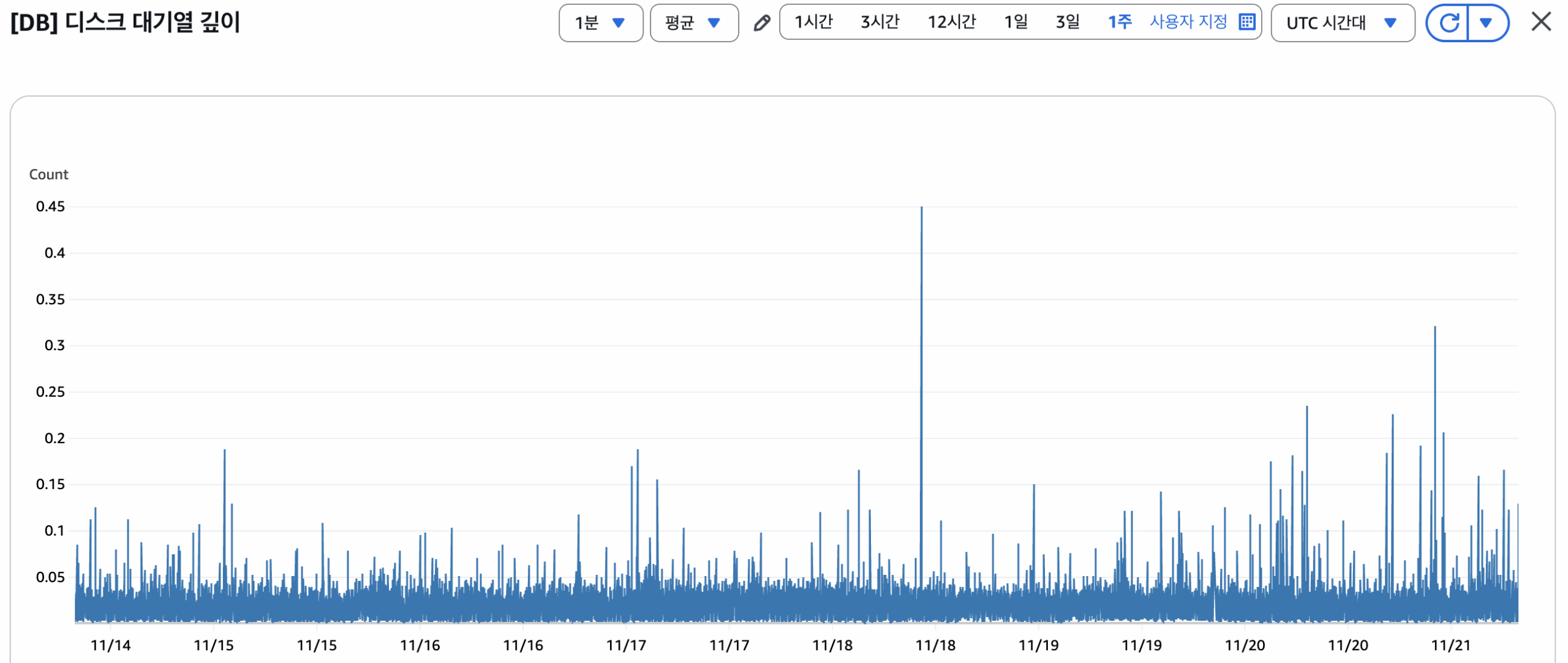
문제가 되었던 디스크 대기열 깊이는 0.5 를 넘지 않는 수준으로 유지되고 있습니다. :)
마치며..
서버 개발자로서, ‘서버가 죽었다’ ‘먹통이다’ 같은 이야기를 들으면 가슴이 철렁하곤 합니다. 하지만 심장 뛰는 상태로 AWS 에 접속하고, 여러 지표를 확인하고, 문제를 확인해 보고, 결국 내가 만든 시스템이 안정적으로 돌아가는 것을 보면 그것만큼 통쾌한 순간이 또 없기도 합니다.
항상 스스로를 ‘여러 경험을 더 하질 못해 안달인 개발자’ 라고 생각해 왔는데, 되짚어 보면 이런 경험 하나하나가 저의 무기이고 강점이 되어가지 않을까 싶습니다. 부디 Google 의 검색엔진이 이 글을 잘 인덱싱해서, 저의 글이 비슷한 문제를 겪고 있는 여러분께 도움이 되었으면 좋겠습니다. :)
